in translation
Performance, kinetic and audio installation, concatenative synthesis, c++. 2019.
New materialism challenges our anthropocentric perspective of the world rooted in a nature-culture dualism. This recent trend in the humanities sees humans and things, but also microbes and plants, as equal entities: human power over things is considered a social construct (Connolly 2013). Though individualism was necessary during the twentieth century in order to obtain political and religious freedom, it casts, today, the shadow of the Anthropocene (Tsing et al. 2017).
in translation is a matter/computer/living being performance that investigates potential conversations between a performer (living being), a computational system (computer), and found objects (matter: branches, tree cones, zip ties, nails, chains, small saw blade, button, plastic bags, toy’s motor, etc.).
This project is seen as the first stage of a longer exploration of the theme of matter/digital/living-being sonic interaction. Following a new materialist framework of investigation, I listen to the voices and poetic forces of everyday objects.
The setup is represented in the figure below. The performer interacts with the found and animated objects in order to generate sounds on a surface called the playground. The sound is picked up by a contact microphone located on the same playground. This signal is interpreted as a live query for a concatenative synthesis algorithm. A synthesized version of this initial signal is then sent over a monitor.
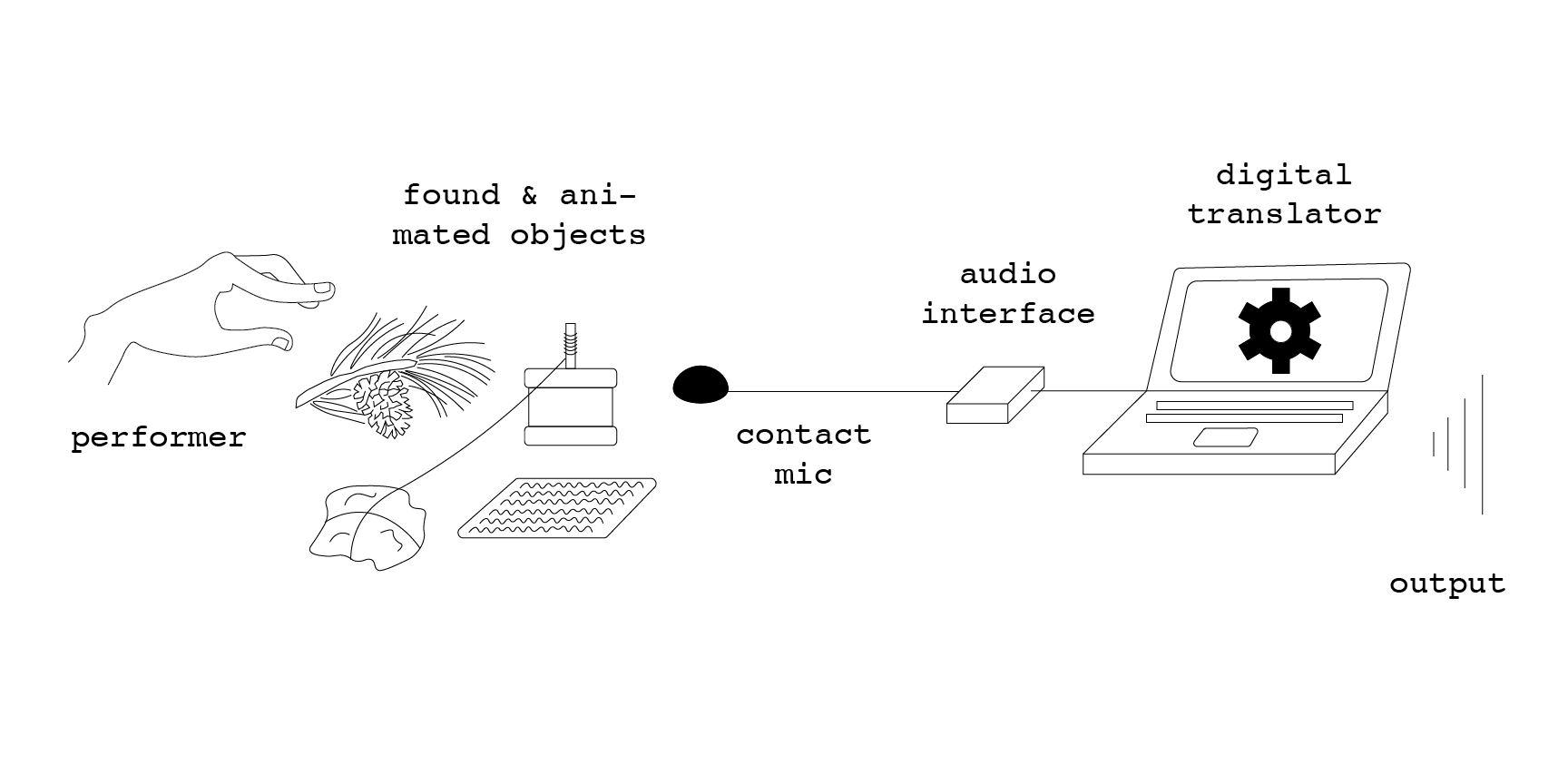
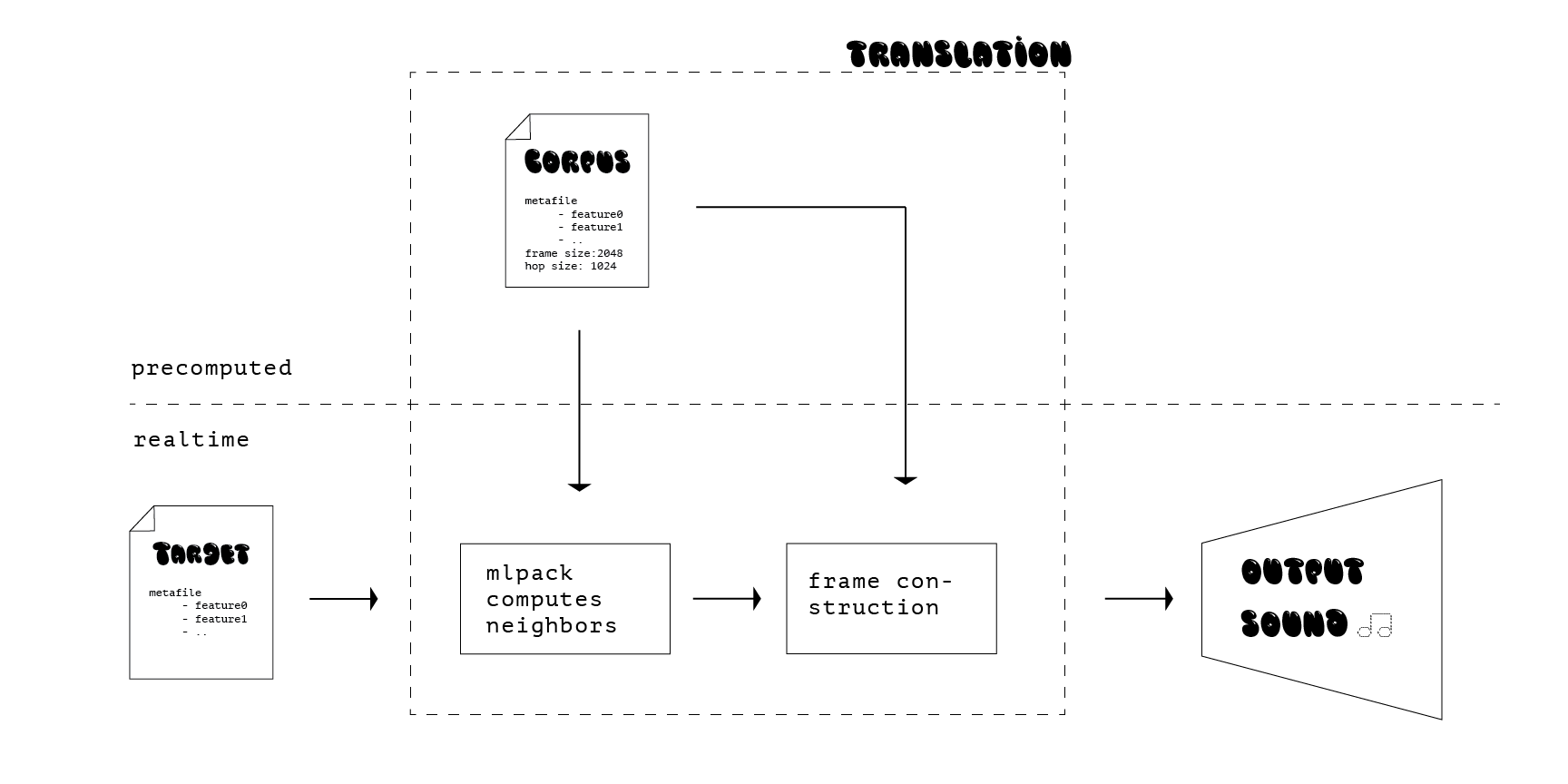
A schematics of the digital system used for translating the analog signal is illustrated in the figure below. The digital translator is based on a concatenative synthesis technique (Schwarz 2006). From a corpus of text-to-speech+trap beats+opera, audio features are calculated using Gist. Audio features include the root mean square of the signal, the energy peak, the zero-crossing rate, the energy difference, the spectral difference, the high-frequency content, and the highest peak. These features are retrieved every frame using a hop size half that frame size and saved in a csv file. This step is precomputed.
The realtime sound target is fed to the system using a contact microphone. The same audio features are extracted from every frame and compared to the corpus in order to determine its nearest neighbor using the mlpack library. The system, then, replaces the incoming target signal frame by this nearest neighbor frame from the corpus and sends it over the output monitor.
c::